__:: Internet: Le protocole TCP ::__ |
Nous y voilà !! On approche du but et aussi de la partie la plus intéressante de ce site. Le protocole TCP (Transmission Control Protocol) est vraiment ce qu'on peut appeler le protocole clé de voûte de toute communication sur réseau informatique et c'est sur lui que reposent toutes les performances que l'on peut attendre d'un tel réseau. De manière très synthétique, ce protocole assure essentiellement deux choses :
1) Le découpage des gros paquets de données en plusieurs petits d'un coté de la chaîne et l'assemblage de plusieurs petits paquets en un gros à l'autre bout de cette même chaîne. De ce fait, TCP est aussi capable de remettre dans l'ordre les données.
2) La fiabilisation du transfert grâce à un principe d'acquittement : si un paquet n'est pas arrivé ou a été corrompu durant le transport, TCP demande sa réémission.
Ce protocole appartient à la couche transport du modèle OSI.
Il est important de préciser qu'au niveau de TCP, un bloc de données
ne s'appelle plus un datagramme mais un segment ... Je suis d'accord,
c'est un peu contraignant mais ça évite de se mélanger
les pinceaux : un datagramme IP et un segment TCP.
Si vous reprenez le fameux modèle OSI, vous constatez que TCP est juste
au-dessus de IP. Cela signifie que du coté du serveur (celui qui envoie
les données) TCP passe des données à IP qui va les transmettre
au modem. Du coté du client - qui reçoit les données -,
c'est IP qui va passer ses données à TCP. Prenons un exemple :
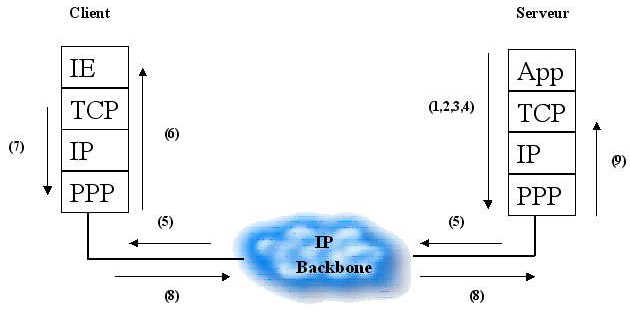
Mettons que le serveur à reçu votre requête et qu'il s'apprête à vous répondre en vous envoyant la page web en question :
1) Depuis la couche applicative (daemon HTTP), toutes les données sont envoyées à la couche transport et donc au protocole TCP. Cette action se fait grâce à ce qu'on appelle des sockets. Je ne vais pas expliquer comment ces petites merveilles fonctionnent car il s'agit là de programmation client-serveur. Allez voir dans les liens si ça vous intéresse.
2) TCP découpe la grosse quantité de données en plusieurs petits paquets numérotés (pour faire simple on va les appeler 1,2,3,...). TCP ajoute un en-tête à chaque paquet (un peu comme IP). Nous verrons son format plus loin.
3) TCP passe le paquet (ou segment) numéro 1 à IP.
4) IP fabrique un datagramme avec un en-tête IP et comme données le segment TCP. Il met dans l'en-tête IP les deux adresses IP : Comme adresse source il indique son adresse, comme adresse cible il indique la votre. Voilà la tête de notre datagramme IP qui encapsule les données:
|
5) Ce datagramme IP est transmis à travers le réseau et arrive finalement sur votre PC.
6) Sur votre PC, le protocole IP décode l'en-tête IP et passe les données du datagramme (ces données constituent un segment TCP) au protocole TCP.
7) TCP constate que ce paquet est le premier d'une longue série, il
le garde donc en mémoire.
En attendant d'autres données, TCP fabrique un paquet vide (sans donnée
utilisateur) et le passe à IP qui va le renvoyer au serveur.
Ce paquet contient juste l'info suivante : "Paquet 1 reçu".
8) IP envoie ce paquet au serveur par l'intermédiaire du réseau.
9) A la réception de ce paquet, le serveur sait que le paquet 1 à été reçu correctement, il envoie donc le paquet 2.... Et ainsi de suite.
Ouf !!! Vous suivez toujours ?? On va faire à nouveau un petit dessin pour que ça passe mieux :
|
Rem : Les numéros correspondent à la description ci-dessus
alors si vous avez du mal, faites une nouvelle petite lecture ... ça
ira mieux après !
Je pense que vous devriez maintenant commencer à comprendre mieux le
fonctionnement en couche, enfin du moins sa représentation. Chaque couche
assure sa propre fonction et s'appuie sur les couches inférieures qui
réalisent pour elle certains services. TCP tout seul est incapable de
transmettre un paquet sur le réseau par exemple ... Et IP ne peut pas
assurer la fiabilité du transfert.
Maintenant que l'on a vu le fonctionnement général de TCP on va
rentrer un peu plus dans le détail.
Nous allons commencer par parler un peu plus précisément des deux fonctions présentées en introduction.
La segmentation : on l'a vu, elle permet de réduire l'encombrement sur le réseau. C'est un peu comme sur l'autoroute, plus il y a de poids lourds, plus ça bouchonne. Sur un réseau informatique, le fonctionnement est le même. Plus les paquets sont gros, plus la congestion (c'est le terme utilisé) est grande. De plus, l'action de découpage limite l'influence de la perte d'un paquet : il n'y a qu'une petite quantité de données à retransmettre en cas de problème et plus la totalité.
L'acquittement : il assure une réelle fiabilité du transfert et permet d'affirmer que l'intégralité des données a été transmise. Dans le cas de la perte d'un segment, tout un processus est mis en place pour assurer sa retransmission. Après avoir attendu un certain temps le paquet (ce temps est paramétrable), le client va automatiquement demander sa réémission. Dans notre exemple, les segments d'acquittement ne contenaient aucune donnée mais ils auraient très bien pu en transporter (par exemple une nouvelle requête HTTP).
La corruption des données : On n'en a pas parlé jusqu'ici mais TCP possède aussi un moyen de vérifier que les données n'ont pas été modifiées durant le transport et qu'elles sont donc identiques à celles qui ont été envoyées. TCP utilise ce qu'on appelle un CRC (Code de Redondance Cyclique). Il s'agit d'un simple chiffre qui est calculé systématiquement de la même manière sur l'ensemble des données contenues dans le segment. La valeur de ce CRC est ensuite ajoutée à l'en-tête. Du coté client, l'en-tête est décodé (on récupère donc le CRC et on le garde en mémoire) puis on recalcule le CRC grâce au même algorithme sur l'ensemble des données. Si les deux CRCs (le CRC reçu et le CRC calculé) sont différents, le segment est déclaré invalide et on demande sa réémission.
Je pense qu'il est temps de donner maintenant le format de l'en-tête TCP. Les explications relatives aux différents champs importants seront données par la suite.
| Bit 0________________________________________________________________________Bit 31 | |||
|
Port Source
|
Port Cible
|
||
|
Numéro de Séquence
|
|||
|
Numéro d'acquittement
|
|||
|
Data
Offset |
Reservé
|
URG
|
Window
|
|
ACK
|
|||
|
PSH
|
|||
|
RST
|
|||
|
SYN
|
|||
|
FIN
|
|||
|
CRC
|
|
||
|
DATA |
|||
Rem: Les six valeurs en colonne entre les champs "Réservé" et "Window" sont appelées les Flags. Ils représentent les options associées au segment TCP en cours. Ainsi, si ce segment effectue un acquittement alors le flag "ACK" aura la valeur "1". Sinon, il aura la valeur "0". Les flags sont en effet des valeurs binaires de 1 bit, ils ne peuvent donc prendre que les valeurs 0 (désactivé) ou 1 (actif).
L'ouverture d'une connexion TCP se fait en trois temps, c'est pourquoi cette
ouverture est appelée en anglais "Three way handshake".
En effet, comme TCP est un protocole fiable, un certain processus est nécessaire
pour démarrer une connexion.
Ceci permet de s'assurer du bon fonctionnement du réseau avant de transmettre
des données.
L'ouverture de connexion utilise les fameux flags que nous avons vu plus haut.
Le flag SYN est mis à 1 par l'entité émettrice qui réclame
l'ouverture d'une connexion.
Il faut savoir qu'une connexion TCP doit être établie dans les
deux sens - Client --> Serveur et Serveur--> Client - avant de pouvoir
espérer transférer des données.
Le processus est donc le suivant :
| Client (A)_________________________________________Serveur(B) |
|
A-------------------------(SYN)---------------------------->
B
|
|
A <---------------------(SYN
/ ACK?)---------------------- B
|
|
A -----------------------(ACK)---------------------------->
B
|
Le client demande tout d'abord l'ouverture de la connexion montante Client
--> Serveur.
Si le serveur a bien reçu cette demande et qu'il est prêt à
établir une connexion avec le client, il lui retourne un segment tout
en acquittant le segment précédent : la connexion montante est
établie. Il demande également l'ouverture d'une connexion descendante
(pour pouvoir lui aussi envoyer des données) par la mise à 1 du
flag SYN.
Finalement, si le client a bien reçu le segment provenant du serveur,
il acquitte ce dernier : les deux connexions sont alors établies.
TCP fonctionne en full-duplex, c'est à dire qu'il existe une connexion montante (Uplink) et une connexion descendante (downlink) qui peuvent transporter des données en même temps : votre machine peut, grâce à ce procédé émettre et recevoir en même temps.
Une autre particularité de TCP est de permettre à plusieurs connexions
de coexister en même temps.
C'est grâce à cette particularité que vous pouvez, par exemple,
relever vos mails pendant que vous êtes en train de visiter un site web.
Très logiquement, on déduit que ces deux actions génèrent
deux flux de données qui ne doivent pas être confondus.
On remarque alors que se pose un problème : toutes ces données
affluent vers votre adresse IP mais cette adresse est le seul identifiant que
l'on possède en l'état actuel de nos connaissances. Il est donc
impossible de différentier les données provenant du serveur web
des données provenant du serveur mail ...
Une solution consistera à attendre la fin d'une des connexions pour lancer
l'autre mais vous vous rendez bien compte que ça ne se passe pas comme
ça et heureusement !!!
Pour résoudre ce problème TCP introduit ce que l'on nomme des
ports. Il s'agit en fait d'un simple numéro (entier) qui désigne
une "porte" d'entrée ou de sortie de données sur votre
machine. Vous constaterez en étudiant le format de l'en-tête TCP
qu'un champ port source et un champ port cible sont présents.
En effet, pour établir une connexion TCP il est necessaire d'identifier
clairement la provenance et la destination des données.
Nous possédons maintenant deux identifiant important :
1) Au niveau IP, l'adresse IP identifie votre machine au sein de réseau
2) Au niveau TCP, un numéro de port identifie le flux de données parmi l'ensemble des données que vous recevez.
Si vous regardez bien le format de l'en-tête, vous constatez que le numéro
de port se code sur 16 bits. Vous savez d'autre part que ce numéro est
un nombre entier. Vous déduisez logiquement sa plage de variation : de
0 à 2^16-1 = 65535.
Pour s'y retrouver plus facilement, un certain nombre de numéros de ports
ont été réservés (de 1 à 1024) et sont toujours
associés à certains types de services. Voici une liste non exhaustive
:
|
Port
|
Service
|
|
7
|
Ping
|
|
11
|
Systat
|
|
13
|
Time
|
|
15
|
Netstat
|
|
22
|
SSH
|
|
23
|
Telnet
|
|
25
|
SMTP
|
|
43
|
Whois
|
|
79
|
Finger
|
|
80
|
HTTP
|
|
110
|
POP3
|
|
119
|
NNTP
|
|
513
|
Rlogin
|
Cette liste est vraiment réduite à son strict minimum. Les valeurs ci-dessus sont vraiment importantes à connaitre.
Rem : Si vous voulez visiter le site www.yahoo.fr, votre navigateur va se connecter à l'adresse IP d'un des serveurs de la compagnie sur le port 80 (voir tableau ci-dessus). Le numéro de port ouvert localement sur votre machine sera lui choisi aléatoirement parmi les ports libres de numéro superieur à 1024. Si vous constatez que le port 80 est ouvert localement sur votre machine, cela signifie qu'un serveur web est lancé sur votre machine et est en attente de connexions (Attention aux attaques dans un tel cas !!).
Rem2: Pour obtenir la liste complète des ports existants, téléchargez la RFC 1700.
La numérotation adoptée par TCP est un peu plus compliquée que celle que nous avons donné dans notre premier exemple. En effet, TCP ne numérote pas les segments en eux même mais les octets contenus dans le segment. Cela permet entre autre au protocole d'acquitter une partie seulement d'un segment en cas de corruption et de conserver la partie correcte tout en redemandant l'émission de la fin du segment.
Si vous regardez bien, les numéros de séquence sont codés
sur 32 bits, ce qui autorise une variation entre 0 et 2^32 - 1 = 4294967295.
Y'a de la marge !!
Le champ "numéro de sequence" souvent appelé SEQ indique
le premier octet dans le segment. Si le bit SYN est positionné (demande
d'établissement d'une connexion), il est alors necessaire d'initialiser
ce numéro de sequence. Le champ SEQ est alors égal à ISN+1
où ISN (Initial Sequence Number) est un numéro calculé
aléatoirement par la machine emettrice. Ainsi il est en principe impossible
de prédire la valeur de l'ISN et ceci est un point très important
que nous reprendrons plus tard.
Rem: Le principe de l'ISN est valable dans les deux sens (Uplink et
Downlink).
Le champ "numéro d'acquittement" couramment appelé ACK indique le numéro de séquence du prochain octet attendu
Cela devient un peu compliqué, je vais donc faire un petit dessin :
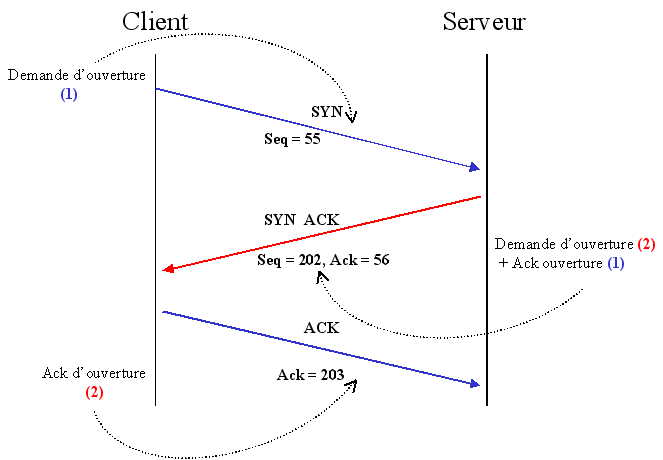 |
Petite précision : Une flèche rectiligne représente un
segment (vous l'aurez compris ...), les flags sont en majuscule au-dessus des
flèches et les champs ACK et SEQ en minuscule sous les flèches.
Je pense que c'est plus clair maintenant ... L'ISN de la connexion (1) vaut
55. Le serveur acquitte ce segment en positionnant son flag ack à 1 et
en mettant la valeur 56 dans son champ ACK. Il envoie aussi l'ISN de sa connexion
qui est 202. Finalement le client acquitte le segment émis par le serveur
(flag ack à 1 + champ ACK à 203).
Le champ Window indique le nombre d'octets que le récepteur peut encore recevoir. En effet, avant de les décoder, le récepteur stocke les segments en mémoire. A chaque segment reçu, cette mémoire se remplit et le champ window est décrémenté d'autant d'octet (nombre d'octets du segment). Si window atteint 0, cela signifie que le recepteur ne peut plus recevoir de données. Le serveur s'arrête donc d'émettre jusqu'a ce que le client ai traité les données déjà reçues.
Bon, il est temps de faire un peu le point ... Je suis d'accord, TCP c'est pas tout simple mais vous verrez qu'on s'y fait vite et qu'après on comprend beaucoup mieux beaucoup de choses : comment obtenir des informations sur quelqu'un (serveur, station de travail, ...), comment se protéger des agressions extérieures, comment doper sa connexion, comment la contrôler ...
TCP apporte donc la fiabilité qu'il manquait à IP : on a la garantie que les paquets émis arrivent à destination. Dans le cas contraire on est averti. TCP assure aussi la remise en ordre des paquets avant la reconstitution. En effet, les paquets d'une même connexion peuvent très bien emprunter des itinéraires différents (merci IP !) sur le réseau et par conséquent arriver dans le désordre. Ca n'est pas grave dans le cas d'une page web mais ça l'est plus dans le cas de fichiers vidéo ou son ...
J'espère que vous avez apprécié ce chapitre, c'est vraiment
la base et si vous voulez aller plus loin, n'hésitez pas ... Il reste
plein de choses à apprendre !
| [ Précédent | Accueil | Suivant ] | |
| © 2001 RésoLution. Tous droits réservés. Contactez le Webmaster. | |